One cannot judge the Maven developer community on one email thread alone. Unfortunately this thread portrays them as an insular group, inward looking and not really understanding a world beyond the one thing that Maven does exceptionally well - building Java apps for enterprise. I have dealt with too many behavioural pathologies in organisations, not to miss seeing this is as being in the same class. But let's just have a look at this in context as to how it started:

I am probably not going to be 100% objective here. I know Marco Vermeulen, the main instigator of SDKMAN! very well. I know his background, how he approaches things and his views in life. He is just an all-round, guitar-playing, good guy, who wants communities to benefit from good stuff.
I also use the SDKMAN! tool nearly everyday. It solves a great number of developer problem for me. I think people misjudge SDKMAN! as simply a package manager.

Call me an anarchist, but I never install Homebrew on any of my Macs. I still use MacPorts for some utilities that I need, but I don't brew stuff. Neither on Linux would I use apt-get, urpmi or yum to install tools like Maven, Gradle or even the Ceylon SDK. Why not? Because all of these tools assume one global version for each package. Even though some tools allow you to manage multiple versions, having them active at the same time are far from a trivial task. Even if the one global version is a good paradigm for system tools, for development tools it is not.
SDKMAN! allows each person on a computer to manage tools and SDK on an individual basis and even have different versions running in different console windows! This is huge for developer productivity. Let's say I am seeing strange behaviour with Maven 3.5.0 or Gradle 3.4 I simply have to do
sdk use maven 3.5.0
OR
sdk use gradle 3.3
and that version will become available on my path. I can then quickly diagnose whether it is behaviour inducesd by a later version of the tool or my own stupidity. This is but one of the simple little things where SDKMAN! is so much more powerful for developers than package management too. (Obviously I am not going to install the latest coreutils package on Linux using SDKMAN! - that is what a package manager is for).
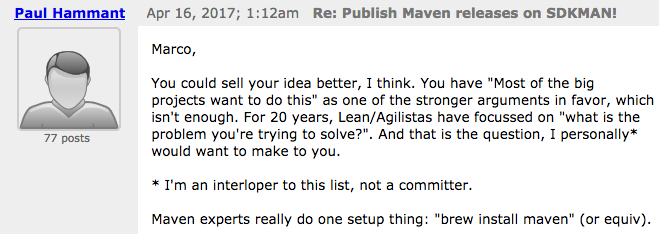
Furthermore Maven experts would recognise that using Maven Wrapper is a far superior solution in most cases than having brew install maven. This is similar to the Gradle Wrapper in that it allows for controlling the version of the build tool within the source repository. This is a far better for reproducible builds.
If you are wondering whether you need SDKMAN! if you are using wrappers, then the quick answer is no. The correct answer is yes, you might need it. Consider that you have a project where the Gradle wrapper is at 2.12, but you want to test the build to see what it will do with say Gradle 3.5 all I need to do is
sdk use gradle 3.5
gradle build
as opposed to the usual
./gradlew build
(I've used Gradle and not Maven as an example here, as there are far more versions available through SDKMAN! than for Maven. The folks at Gradle groks what SDKMAN! is about). A little research, a little bit of asking around might just be better than shooting from the hip like one contributor to the conversation:

This is just arrogance. My immediate perception is we have someone here, who did not even bother to research what SDKMAN! is, and bound by whatever restricts his viewpoint, simply slags off the product. This is way uncool. It reeks of insularity in this community (I can only hope it is an attitude of a minority).
Then there is the release process:

Granted there has to be some manual steps involved in releasing software under the Apache Software Foundation, but does the Maven release process really need 30 steps? Apache Groovy don't need this many and their publication to SDKMAN! is automated. This tells me two things, which I admit I can be wrong about:
- Firstly the Maven developer community is too inward looking
- Secondly Maven as a build tool is simply not good enough to automate at scale beyond building Java projects. (I know you can try to build other stuff with it, but do you still have a good quality of life after trying to do that at scale?)

He came with good intentions upon an invite and you the Maven tool development community have hated him for it. You need to go back and look at yourselves and look at your process, because from where I stand there is something most definitely wrong somewhere. Maven has been a revolutionary change to software development efficiency when it came about, but where are you as custodians standing now?
You are obviously at right to keep your process and your community the way you want, but if you want to close your borders don't expects tourists and investors to come knocking. They will go elsewhere and you'll remain a closed an insular community.
P.S. Leiningen, Kobalt, Gradle, Ant, SBT are all on SDKMAN! You can even manage JDK versions with it. If you consider Maven is too precious to mix with the rest, let it be so.